


|
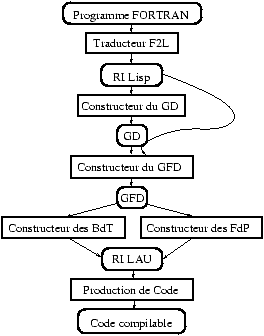
|
Considérons l'exemple suivant que nous allons retrouver tout au long de cette section.La représentation intermédiaire qui lui correspond estPROGRAM relax INTEGER n,m,i,j REAL a(100,100) DO i=1,n DO j=1,m a(i,j)=f(a(i-1,j),a(i,j-1)) (v1) END DO END DO END(df relax nil (prog () (integer n nil) (integer m nil) (integer i nil) (integer j nil) (real a (100 100)) (real f nil) (for (i 1 1 n) (prog () (for (j 1 1 m) (prog () (aset a i j (f (aref a (- i 1) j) (aref a i (differ j 1))))))))))
|
Le GD générique du programme relax ne comporte qu'un sommet v1. La liste de ses arcs est :Le graphe des dépendances met en lumière les conflits entre opérations, mais ce n'est pas forcément la structure de choix pour la détection du parallélisme. En effet ce graphe présente deux défauts :(v1 v1 PC (aref a i j) (aref a (- i 1) j)) (v1 v1 PC (aref a i j) (aref a i (- j 1)))Chaque arc comporte la source et la destination de la dépendance, le type de la dépendance et les références aux cellules mémoires sur lesquelles porte la dépendance. Le schéma correspondant est :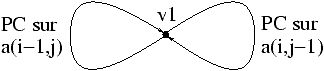
|
Le GFD du programme relax est :Le GFD permet de transformer un programme à contrôle statique en un programme à assignation unique (plus de détails seront donnés en 7.1.1). Dans un tel programme il n'y a plus de réutilisation des variables, il ne reste que des dépendances du type PC. Un ordre partiel <// moins contraignant peut donc être trouvé. Le programme est mieux parallélisé, par contre la taille de la mémoire utilisée est bien plus importante.Source de a(i-1,j) dans v1 ; * IF [ (i-2>=0) ] -> (v1,i-1,j) Source de a(i,j-1) dans v1 ; * IF [ (j-2>=0) ] -> (v1,i,j-1)Ce graphe est composé d'un sommet v1 portant deux boucles :
|
La base de temps trouvée par PAF pour le programme relax est :Le compilateur PAF synthétise les résultats du GFD, du module de calcul de la base de temps et du module de calcul de la fonction de placement dans un seul fichier au format LAU (i.e. langage à assignation unique).q(v1,i,j)=i+j-2 .Cela signifie que toutes les opérations de l'instruction v1 qui se trouvent sur la même anti-diagonale de l'espace d'itération s'exécutent au même instant (voir la figure ci-dessous).La fonction de placement du programme est :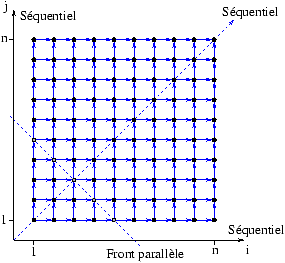 p(v1,i,j)=i-1 .Toutes les opérations sur une même ligne de l'espace d'itération doivent être placées sur le même processeur pour minimiser le coût des transferts de données. Il est à noter que la fonction de placement p(v1,i,j)=j-1 convient aussi, puisque le GFD est symétrique par rapport à la diagonale de l'espace d'itération. Ces deux placements minimisent les communications car l'une des deux données nécessaires à un calcul est située sur le processeur exécutant ce calcul. Évidement, une solution encore meilleure du point de vue de la minimisation des communications, est d'exécuter toutes les opérations sur le même processeur, mais plus aucun parallélisme n'est alors possible. Une des difficultés du calcul des fonctions de placement est justement d'éviter cette perte de parallélisme.
p(v1,i,j)=i-1 .Toutes les opérations sur une même ligne de l'espace d'itération doivent être placées sur le même processeur pour minimiser le coût des transferts de données. Il est à noter que la fonction de placement p(v1,i,j)=j-1 convient aussi, puisque le GFD est symétrique par rapport à la diagonale de l'espace d'itération. Ces deux placements minimisent les communications car l'une des deux données nécessaires à un calcul est située sur le processeur exécutant ce calcul. Évidement, une solution encore meilleure du point de vue de la minimisation des communications, est d'exécuter toutes les opérations sur le même processeur, mais plus aucun parallélisme n'est alors possible. Une des difficultés du calcul des fonctions de placement est justement d'éviter cette perte de parallélisme.
|
Il suffit de remarquer que l'union convexe de deux segments perpendiculaires est un plan ; le nombre de points à itérer peut passer de n à n2.La solution est de ne pas construire l'enveloppe convexe et de générer des nids de boucles différents pour chaque espace d'itération [16, 18]. Pour l'instant le compilateur PAF peut générer du code pour la CM-2 [51], pour le Cray Y-MP [40] et pour la MasPar [18].
La relation entre la base de temps, la fonction de placement et les compte-tours des boucles du programme relax est :La matrice de passage est uni-modulaire donc le programme parallèle peut être généré avec des boucles de pas 1 :
æ
è
q(v1,i,j) p(v1,i,j) ö
ø= é
ë
1 1 1 0 ù
ûæ
è
i j ö
ø+ æ
è
-2 -1 ö
ø. Le programme ci-dessus pour être complet devrait expliciter les communications entre les processeurs. Il peut cependant s'exécuter sur une machine avec une mémoire partagée. Le nouvel espace d'itération est décrit par la figure suivante.DO t=0,2*n-2 DO ALL p=max(0,t-n+1),min(n-1,t) a(p+1,t-p+1)=f(a(p,t-p+1),a(p+1,t-p)) END DO END DO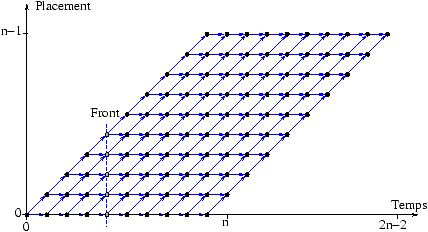
|