| Chapter 14 |
Génération de code |
|
À ce niveau de l'étude les réductions et les scans sont
extraits du programme source et une base de temps a été
calculée. La dernière étape est la génération de
code du programme parallèle. Ce chapitre donne les
premières briques d'une génération automatique de
code. Tout d'abord il est parfois nécessaire d'aligner
les vecteurs directeurs des opérateurs Scan sur les
dimensions des tableaux pour pouvoir utiliser les
primitives de calculs de scans de la machine cible.
La section 12.1.1 indique sous quelles conditions
ce changement de base peut s'effectuer.
Il est ensuite montré que deux squelettes différents de
code parallèle peuvent être générés pour un scan
donné. Il est difficile de dire lequel des deux codes est
le plus efficace. Nous présentons tout de même une
heuristique de choix du code en fonction du type de scan
et de la machine cible pour laquelle le code doit être
généré. Les différences entre les deux codes sont
explicitées sur un exemple.
| 14.1 |
Génération de code pour réductions et scans |
|
Calculer une base de temps permet de trouver
un bon programme parallèle pour une machine idéale
(nombre infini de processeurs, UAL avec un nombre infini
d'entrées). Cependant, sur une machine réelle, le
programme parallèle brut peut avoir des performances
décevantes. La phase de génération de code doit donc
être optimisée pour tenir compte des particularités
d'une machine réelle.
| 14.1.1 |
Alignement des directions d'un scan |
|
Pour pouvoir utiliser les primitives de réduction ou de scan
implantées sur les machines actuelles, les directions de
l'opérateur Scan doivent nécessairement être alignées avec
les dimensions des tableaux (e.g. pour une matrice, il n'est
possible de sommer que des lignes ou des colonnes).
En conséquence toutes les réductions ou scans détectés avec
des vecteurs de directions non canoniques ne peuvent pas être
exploités directement. Il est toujours possible d'effectuer un
réarrangement des données à l'exécution lors de la phase
de stockage des valeurs du scan. L'inconvénient de cette méthode
est d'augmenter le temps d'exécution du programme. Autant effectuer
directement le changement de base équivalent au niveau de l'opérateur Scan
dans le texte du programme parallèle. La proposition suivante
montre qu'il est possible, sous certaines conditions, de modifier
les vecteurs directeurs d'un opérateur Scan sans modifier les
valeurs calculées par cet opérateur.
Proposition 12 [Changement de base de l'opérateur Scan]
Si T est une transformation affine bijective et Tl la
transformation linéaire associée, il vient :
|
|
|
| º |
| Scan(T( D |
),(Tl(ei)) |
|
,b,d° T-1,
g° T-1)
. |
|
|
-
Preuve:
-
Notons u le tableau multi-dimensionnel calculé par le premier
Scan et v celui calculé par le second.
D'après la définition du Scan, v est défini par :
|
" zÎ T( D),
v(z)=
|
ì
ï
ï
ï
ï
ï
ï
ï
ï
ï
ï
ï
í
ï
ï
ï
ï
ï
ï
ï
ï
ï
ï
ï
î |
| si |
|
| |
g(T-1(z)) |
| sinon si |
|
| |
|
| ... |
| sinon si |
|
| |
| fT(z,v(max |
|
(z-Tl(ek-1)))) |
|
| sinon |
fT(z,v(z-Tl(ek)))
, |
|
|
D'après la définition du minimum dans un convexe (voir 9.2),
désigne le vecteur
|
|
|
|
(n1,...,nk)=
lexmax(µ1,...,µkÎN |
k |
T(z)- |
|
µi.Tl(ei)Î T( D)) |
|
|
|
" zÎ D,
v(T(z))=
|
ì
ï
ï
ï
ï
ï
ï
ï
ï
ï
ï
ï
í
ï
ï
ï
ï
ï
ï
ï
ï
ï
ï
ï
î |
| si |
|
| |
g(z) |
| sinon si |
|
| |
|
| ... |
| sinon si |
|
| |
|
| sinon |
f(z,v(T(z)-Tl(ek)))
, |
|
|
Il en découle que, sur D, u est identique à v° T.
Le principe du changement de base est de trouver l'application T
transformant les directions du scan en vecteurs colinéaires aux
vecteurs canoniques. Une méthode est de compléter la famille des
directions de l'opérateur Scan pour obtenir une base (dans le cas
d'un opérateur Scan multi-directionnel c'est possible si ses
directions sont indépendantes). Il suffit ensuite d'inverser la
matrice formée par la base de vecteurs.
Un problème est que nous ne manipulons que des domaines de
définition qui sont des convexes (plus exactement des polyèdres
entiers, c'est-à-dire les points entiers inclus dans le polyèdre).
Or le changement de base implique une transformation du domaine
de définition D de la récurrence et seule une
transformation uni-modulaire
1
transforme un polyèdre entier en un autre polyèdre entier [45].
En conséquence, il n'est pas toujours possible d'appliquer
un changement de base pour que les directions de l'opérateur
soient alignées suivant les vecteurs canoniques. Pratiquement
cela signifie que les primitives des machines parallèles ne
peuvent pas toujours être utilisées ; il faut soit exécuter
ces scans en séquentiel, soit écrire des procédures
plus complexes (mais forcément moins optimisées) que les
primitives disponibles.
Considérons le scan ci-dessous qui calcule le tableau
multi-dimensionnel u :
Scan( { 1 <= i <= n, 0 <= j <= m, 0 <= k <= l }, ( [0,1,1] ),
+, s[i,j,k], s[i,j,k] )
La famille de vecteurs
|
|
æ
ç
ç
è |
|
|
|
ö
÷
÷
ø |
æ
ç
ç
è |
|
|
|
ö
÷
÷
ø |
æ
ç
ç
è |
|
|
|
ö
÷
÷
ø |
,
|
Scan( { 1 <= i <= n, 0 <= j+k <= m, 0 <= k <= l }, ( [0,0,1] ),
+, s[i,j+k,k], s[i,j+k,k] )
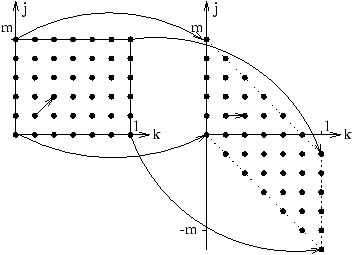
La transformation du domaine de définition (pour un i fixé)
et de la direction de l'opérateur Scan est illustrée sur le schéma
ci-dessous.
| 14.1.2 |
Les deux types de génération de code |
|
Nous cherchons dans la suite de cette section à générer du code
efficace pour un opérateur Scan donné. La tâche est relativement
complexe car un opérateur Scan peut représenter un nombre
de scans dépendant des paramètres de structure. Il est donc possible
d'extraire deux types
de parallélisme d'un tel opérateur : le parallélisme intra-scans
(en utilisant l'associativité des opérateurs) et le parallélisme
inter-scans (en utilisant le fait que deux scans peuvent être calculés
simultanement).
L'algorithme qui vient immédiatement à l'esprit pour implanter un
opérateur Scan est d'effectuer chaque scan dès que toutes ses
données sont prêtes. Nous appelons le code correspondant à cet
algorithme le code naïf.
L'inconvénient de ce code est qu'il concentre tout le calcul dans un
seul front. C'est sans effet sur une machine idéale capable de calculer
un scan en une unité de temps, par contre c'est préjudiciable sur une
machine n'ayant pas de primitive efficace de calcul de scan.
Un autre schéma de génération de code est d'effectuer les
opérations de calcul des scans au plus tôt. Ce schéma est
plus particulièrement applicable aux scans de type réduction.
En effet, dès qu'une donnée d'une réduction est prête il
est possible de l'intégrer au résultat partiel de cette
réduction. Le code correspondant à ce schéma de génération
de code est appelé code asap, de l'acronyme anglais As Soon As Possible.
Considérons la réduction calculant la somme des éléments
a(1) à a(n). Supposons que la base de temps pour le
tableau a (i.e. la date à laquelle ses différents
éléments sont prêts) soit qa(i)=n-i. La génération
de code naïve va produire le programme suivant :
DO t=0,n-1
C Calcul des éléments de a
IF (t.EQ.n-1) THEN
s=sum(a,1,n)
END IF
END DO
Sur la machine idéale la valeur de s est prête au temps
n, mais sur une machine réelle, le calcul de la somme prendra
un temps approximativement inversement proportionnel au nombre de
processeurs qu'elle possède. La somme ne sera donc disponible que
vers le temps n+n/p. Or il est possible d'écrire un code
optimal même pour une machine mono-processeur :
DO t=0,n-1
C Calcul des éléments de a
s=s+a(n-t)
END DO
La valeur de s est alors disponible au temps n.
Dans ce code les données sont accumulées sur s
dès qu'elle sont prêtes, il s'agit du code asap.
Nous verrons, dans la section 12.1.4, qu'il est n'est pas
facile de déterminer dans le cas général lequel du code naïf
ou asap est le plus efficace.
| 14.1.3 |
Génération de code naïve |
|
Pour formaliser la génération de code naïve, considérons
un scan quelconque :
|
Scan(
D |
,(ei) |
|
,b,d,g)° f
,
|
DO t=t1,t2
C
Calcul des vecteurs d'itération des résultats partiels de scans
C
à effectuer au temps
t. Seul le
dernier résultat de
chaque scan
C
est pris en compte (calcul du max).
Soit I l'ensemble {z | q(z)=t}Ç
max
e1,...,ek D'( D')
C
Exécution, en parallèle, des scans dont le dernier résultat partiel
C
est prêt. Vu la manière dont est calculé l'ordonnancement il est
C
certain que toutes les données de ces scans sont prêtes.
DO ALL zÎI
C
L'ensemble
P(
z) regroupe les vecteurs d'itérations des données
C
du scan dont le vecteur du dernier résultat est
z.
Appliquer le scan sur P(z)
2
END DO
END DO
Dans ce code les scans ne sont déclenchés que lorsque toutes
leurs données sont prêtes. Plus exactement un scan est lancé
lorsque le calcul de son dernier résultat partiel utilisé
peut être effectué. Le scan est effectué avec toutes ses données.
Cela signifie que, si le dernier résultat partiel utilisé
n'est pas le dernier résultat partiel du scan, des opérations inutiles
sont effectuées. Ces opérations inutiles correspondent à des
opérations inutiles dans le programme séquentiel source.
| 14.1.4 |
Génération de code asap |
|
Nous reprenons dans cette sous-section les notations déjà définies
pour exprimer le code naïf (cf section 12.1.3).
De façon formelle, le principe du code asap est d'accumuler, dans
un premier temps, toutes les valeurs précédant (au sens du parcours
du scan) un point z de D' dans une variable temporaire associé
à z. Dans un second temps une primitive de calcul de scan est appliquée
sur les variables temporaires associées aux points de D'.
Pour tout point z de D définissons S(z) le point tel que :
|
|
|
|
(l1,...,lk)=
lexmin(µ1,...,µkÎN |
k |
z+ |
|
µi.eiÎ f( D)) |
|
|
.
|
|
" z,z'Î D× D |
,
zº |
|
z' Û S(z)= S(z')
.
|
DO t=t1,t2
C
L'ensemble I regroupe les vecteurs d'itération des données des scans
C
calculées au cycle précédent.
Soit I l'ensemble {z | qd(z)=t-1}
C
L'ensemble I est quotienté : les vecteurs d'itération des données à
C
accumuler sur le même temporaire se retrouve dans la même classe
C
d'équivalence.
Quotienter I par º S
Soit C l'ensemble des classes d'équivalence de I
C
Les différentes données peuvent être accumulées en parallèle dans
C
leurs variables temporaires respectives.
DO ALL E Î C
C
Calcul du vecteur d'itération s associée à la variable temporaire
C
qui sert d'accumulateur pour une classe d'équivalence.
Soit s l'image par S d'un élément de E
C
Accumulation des données d'une classe d'équivalence sur sa
C
variable temporaire.
temp(s)=réduction(temp(s),E)
C
Si les dernières valeurs d'un scan viennent d'être accumulées, il
C
faut effectuer le scan partiel sur les temporaires d'accumulation.
IF s=maxe1,...,ek D(s) THEN
Soit F l'ensemble P(s)
Appliquer le scan sur temp( S(F))
END IF
END DO
END DO
Le tableau temp est un tableau temporaire représentant
l'espace d'accumulation des scans finaux. L'intérêt de ce code est
que les opérations calculant les scans se font au plus tôt. Il n'y a
pas d'amélioration sur la latence théorique : t2+1.
En revanche les opérations sont mieux réparties,
contrairement à la génération de code naïve qui produit
un code nul pour la plupart des fronts et concentre le calcul
des scans sur quelques fronts. Le gain obtenu par l'utilisation
du code asap dépend complètement de la nature du scan,
de la base de temps de ses données et du type des autres
opérations à exécuter entre t1 et t2.
Si la récurrence est un scan non-dégénéré,
les deux codes sont identiques car S est une bijection.
Il n'est donc pas possible d'accumuler par anticipation.
Toutes les opérations sont effectuées par le scan final.
Ce cas pourrait être optimisé si des primitives de calcul
incrémental de scans existaient sur la machine cible
(i.e. des primitives capables d'initier un calcul de scan
avec des données incomplètes puis de mettre à jour
les résultats au fur et à mesure de la disponibilité des
données restantes). Pour l'instant aucune machine parallèle
ne dispose de telles primitives ; elles sont très difficiles à
programmer de façon efficace.
Dans le cas où le scan est dégénéré, il est
généralement possible de prendre de l'avance dans les opérations.
Plus le scan est dégénéré et plus le nombre de variables
d'accumulation est faible (pour une réduction une seule
variable est nécessaire). L'intérêt d'avoir un faible
nombre de variables d'accumulation est qu'il y a un plus grand
nombre de données à accumuler sur chaque variable, donc
un plus grand nombre d'opérations à effectuer à l'avance.
Pour pouvoir prendre de l'avance sur le calcul du scan, il faut
aussi que la base de temps des données soit favorable,
c'est-à-dire que les dates auxquelles les données sont prêtes
doivent être bien réparties entre t1 et t2 et que
l'intervalle entre t1 et t2 doit être suffisamment grand.
Sinon, seuls quelques fronts entre t1 et t2
comporteront des pré-calculs pour le scan.
Par exemple, si q est constante, le code généré va
se résumer à une réduction au temps t1
(égal, ici, à t2) suivi d'un scan sur une valeur.
En fait, il est impossible de prendre de l'avance sur les
opérations du scan puisque toutes les valeurs sont prêtes
en même temps. Il faut noter que même dans ce cas une
optimisation est effectuée puisque le scan est remplacé
par une réduction (une réduction est généralement
exécutée deux fois plus rapidement que le scan correspondant).
| 14.2 |
Comparaison du code naïf et du code asap |
|
Dans cette section nous tentons de quantifier le gain,
en terme de temps d'exécution, apporté par le code asap
par rapport au code naïf.
L'ensemble des opérations à exécuter à
la date t, hors les opérations du scan, est noté
O(t). Le temps mis pour exécuter un ensemble
d'opérations O sur la machine cible est noté d(O).
Soit Sn(t) l'ensemble des opérations nécessaires au
calcul des scans du code naïf qui s'exécutent au temps t.
Avec ces notations le temps d'exécution du code naïf est :
Notons Sc(t) l'ensemble des opérations nécessaires au calcul
des scans du code asap qui s'exécutent au temps t.
Enfin, notons Rc(t) l'ensemble des opérations
nécessaires au calcul des réductions d'accumulation du front t.
Avec ces notations le temps d'exécution du code asap s'écrit :
|
dc=
|
|
d( O(t)È Sc(t)È Rc(t))
|
Envisageons d'abord le cas d'un modèle d'exécution MIMD,
c'est-à-dire d'une machine qui peut exécuter plusieurs
opérations différentes dans le même cycle. L'intérêt
de ce modèle est que les temps d'exécution des réductions
d'accumulation du code asap peuvent être recouverts
par les temps d'exécution des opérations classiques. Plus
formellement, il est possible que les durées :
d( O(t)È Sc(t)È Rc(t))
,
soient égales aux durées
d( O(t)È Sc(t))
.
Il est par contre peu probable que les temps d'exécution des scans
du code naïf soient recouverts par les temps d'exécution des opérations
classiques. En effet, ces scans traitent généralement un grand nombre
de données, donc ont un temps d'exécution élevé même sur une machine
parallèle. Le code asap est efficace pour le mode de programmation MIMD
si peu de réductions d'accumulation se retrouvent dans le même front
et si elles traitent un faible nombre de données.
Considérons le scan calculant les sommes partielles d'un
tableau a (le tableau possède 2*n éléments) :
Scan( { -1 <= i <= 2*n-1 }, ( [1] ), +, a[i], 0 )
Supposons qu'un élément a(i) du tableau soit
prêt à la date q(i)=ë i/2 û
et que la fonction d'accès au scan soit f(i)=2i+1.
Supposons enfin que la clause accédant au scan soit
définie sur {0,...,n-1}.
À chaque instant t deux valeurs sont prêtes,
a(2*t) et a(2*t+1). Elles doivent être
accumulées dans temp(2*t+1).
Au temps t il est possible d'avancer l'exécution des
deux opérations suivantes :
temp(2*t+1)=a(2*t)
temp(2*t+1)=temp(2*t+1)+a(2*t+1)
Il est probable que la plupart des O(t) ne comportent pas
un nombre d'opérations multiple du nombre de processeurs. Dans le
front t, la dernière vague d'opérations n'est pas complète
et les deux accumulations peuvent y prendre place sans modifier
le temps d'exécution du front.
En définitive le scan à exécuter dans le front n traitera
deux fois moins de données que le scan complet. Dans cet exemple
le code asap s'exécute environ deux fois plus rapidement que le
code naïf.
Il est à noter que le code asap est plus efficace si les
scans représentés par l'opérateur Scan sont très
dégénérés. Le cas idéal est la réduction,
car plus aucun scan final n'est nécessaire.
Si le code asap génère trop d'opérations d'accumulation
par front, leurs temps d'exécution n'est plus recouvert
par les temps d'exécution des opérations classiques. Les
performances du code classique se rapprochent de celles obtenues
avec un modèle d'exécution SIMD.
Comparons maintenant les temps d'exécution des codes naïf et asap
dans le cadre d'un modèle de programmation data-parallèle (SIMD).
L'exécution en parallèle d'opérations différentes
est interdit. Cela signifie que si O1 et O2 sont deux ensembles
d'opérations de natures différentes alors il vient
d(O1È O2)=d(O1)+d(O2).
La différence des durées d'exécution des codes s'écrit alors :
|
dc-dn
= |
|
d(Rc(t))
+ |
|
d(Sc(jk))
- |
|
d(Sn(ik))
|
Soit (nij)iÎ Nm*, jÎ Nai* la famille
des nombres de données traitées par les réductions d'accumulation.
La famille est doublement indicée pour décrire le fait que certaines
réductions sont sensées s'exécuter au même temps : nij1
et nij2 représentent le nombre de données que traitent deux
réductions ordonnancées au même instant.
De la même façon, nous définissons
(ncij)iÎ Nmc*, jÎ Nbi* la famille des
nombres de données traitées par les scans du code asap, la
somme de ces nombres est notée Nc.
Enfin, soit (nnij)iÎ Nmn*, jÎ Ngi*
la famille des nombre de données traitées par les scans du code naïf.
La somme de ces nombres est notée Nn.
La somme des nombres de la famille
(nij)iÎ Nm*, jÎ Nai*
vaut Nn+a-Nc où a est la somme des ai.
-
Preuve:
-
Pour prouver cette affirmation, il faut remarquer que Nc donne
le nombre de variables d'accumulation, c'est-à-dire le nombre
de points entiers dans le domaine D'.
De plus toutes les données des scans sont accumulées et les
réductions modifiant une variable d'accumulation doivent prendre
en compte la valeur de cette variable. Or, il n'existe que
a-Nc réductions modifiant les variables d'accumulation,
les autres initialisent ces variables.
De plus la somme b des bi est égale à la somme
g des gi.
-
Preuve:
-
Évident car il y a autant de scans dans le code asap
que dans le code naïf.
Notons dr((nj)jÎ Ns*) le temps nécessaire
à la machine cible pour calculer s réductions en parallèle
(sachant que la réduction j traite nj données).
Un opérateur similaire, ds, est défini pour les scans.
Avec ces notations il est possible de préciser la valeur de la
différence des durées d'exécution :
|
dc-dn=
|
|
dr((nij) |
|
)
+ |
|
ds((ncij) |
|
)
- |
|
ds((nnij) |
|
)
.
|
-
Cas d'une machine séquentielle
- :
Les temps de calcul des réductions et des scans sont
|
dr((nj) |
|
)=
dr((nj) |
|
)= |
|
(nj-1)
.
|
dc-dn=(Nn+a-Nc-a)+(Nc-b)-(Nn-g)=0
.
Ceci montre que les deux codes effectuent le même nombre d'opérations.
- Cas d'une machine parallèle sans primitive de calcul de scans
- :
Pour ce genre de machine l'intérêt du code asap est que
plusieurs réductions pourront être exécutées dans le
même temps.
Pour exprimer les fonctions dr et ds il faut introduire
la famille de booléens Bk,l associée à une famille
de nombres de données (nj)jÎNs* (nous supposons, de plus,
que n1 est le maximum de la famille). Cette famille est définie par :
|
" kÎN |
|
, " lÎNs*, Bk,l=(nl>k)
|
|
dr((nj) |
|
)=
dr((nj) |
|
)= |
|
|
é
ê
ê
ê |
|
|
ù
ú
ú
ú |
.
|
|
|
dc-dn=
|
|
|
|
|
é
ê
ê
ê |
|
|
ù
ú
ú
ú |
+ |
|
|
|
|
é
ê
ê
ê |
|
|
ù
ú
ú
ú |
- |
|
|
|
|
é
ê
ê
ê |
|
|
ù
ú
ú
ú |
. |
|
|
- |
|
nn1i
£ dc-dn <
|
|
n1i
+ |
|
nc1i
.
|
-
Preuve:
-
En effet, puisque é xù est compris entre x et x+1,
la différence des durées est encadrée par :
et
Or, d'après la définition des familles booléennes :
|
|
|
| = |
| (Nn+a-Nc-a)+(Nc-b)+(Nn-g)=0
. |
|
La génération du code asap est intéressante lorsque
la différence des durées est proche de la borne inférieure
(il s'agit d'une valeur négative).
C'est le cas lorsque les deux premiers termes de l'expression
(12.2) sont peu perturbés par l'arrondi par valeur
supérieure (i.e. quand la valeur du terme écrit avec l'arrondi
est peu différente de la valeur du terme écrit sans l'arrondi)
et lorsqu'au contraire cet arrondi augmente sensiblement le poids
du dernier terme. Les conditions pour que l'arrondi ne perturbe
pas un terme dépendent de trop de paramètres. Par contre, il
existe une condition simple à exprimer et suffisante pour qu'un
terme soit fortement perturbé par l'arrondi. Prenons, par exemple,
le troisième terme de (12.2) ; il suffit que les gi
soient négligeable devant p. Dans ce cas la différence entre
le terme écrit avec et sans l'arrondi est très proche de
åi=1mnnn1i . Sous cette hypothèse
la différence des deux durées est majorée par
La différence est négative si la valeur absolue du premier
terme est grande devant les valeurs des deux derniers termes.
Les gi étant petits le premier terme est de l'ordre de
-Nn. Les deux autres termes sont d'autant plus petits que les
ai et les bi sont grands et que les (nij)
et les (ncij) pour i fixé sont équilibrés.
Dans le cas où :
-
les gi sont égaux à 1 ;
- les (nij) pour i fixé sont identiques
(idem pour les (ncij)) ;
- les ai sont tous égaux à a/m
et les bi sont tous égaux à b/mc,
la différence est alors majorée par :
Si le nombre de réductions d'accumulation est grand par rapport
au nombre de fronts dans lesquelles elles s'exécutent il est
intéressant de générer un code asap.
En résumé, la génération du code asap est rentable si :
-
les scans du code naïf ne peuvent pas être exécutés
en parallèle ;
- les réductions d'accumulation du code asap sont nombreuses,
peuvent être exécutés en parallèle et traitent
approximativement le même nombre de données ;
- les scans du code asap peuvent aussi être exécutés
en parallèle ou sont inexistants comme dans le cas où
l'opérateur Scan désigne en fait une réduction.
- Cas d'une machine parallèle avec primitive de calcul de scans
- :
Nous étudions le cas où uniquement le parallélisme relatif au
calcul des réductions et des scans est exploité. Le parallélisme
entre les scans n'est pas utilisé.
Les scans sont supposés implantés avec la technique du partitionnement
décrite dans la section 11.2. Pour une famille de nombres de
données (nj)jÎNs* les fonctions de durée s'écrivent :
|
|
|
ds((nj) |
|
)=2 |
æ
ç
ç
è |
|
|
|
é
ê
ê
ê |
|
ù
ú
ú
ú |
+p |
ö
÷
÷
ø |
|
|
dr((nj) |
|
)= |
|
|
é
ê
ê
ê |
|
ù
ú
ú
ú |
+p
. |
|
|
|
|
|
|
dc-dn |
= |
|
|
|
æ
ç
ç
è |
|
|
é
ê
ê
ê |
|
ù
ú
ú
ú |
+p |
ö
÷
÷
ø |
+2 |
|
æ
ç
ç
è |
|
|
|
é
ê
ê
ê |
|
ù
ú
ú
ú |
+p |
ö
÷
÷
ø |
|
| |
- |
|
2 |
|
æ
ç
ç
è |
|
|
|
é
ê
ê
ê |
|
ù
ú
ú
ú |
+p |
ö
÷
÷
ø |
. |
|
|
|
|
|
|
-2g(p+1)
£ dc-dn <
|
|
+(a+2b)(p+1)
.
|
-
Preuve:
-
D'après l'expression (12.3) la différence des
durées est comprise entre :
|
|
|
|
|
|
(nji-1)
+2 |
|
|
(ncji-1)
-2 |
|
|
(nnji-1)
|
|
|
| p |
|
-2g(p+1)
,
|
|
|
|
|
|
|
(nji-1)
+2 |
|
|
(ncji-1)
-2 |
|
|
(nnji-1)
|
|
|
| p |
|
+(a+2b)(p+1)
.
|
(Nn+a-Nc-a)+2(Nc-b)-2(Nn-g)=Nc-Nn
.
D'où le résultat.
La génération du code asap est intéressante pour ce type
de machine lorsque les conditions suivantes sont réunies :
-
La borne inférieure de l'expression (12.3) est la plus
petite possible. C'est à dire que Nc est minimale
(l'opérateur Scan représente une réduction et non
un scan) et Nn est grand
(la réduction traite un grand nombre de données).
- La différence doit être proche de sa borne inférieure.
Si, déjà, la récurrence est une réduction le deuxième terme
de l'expression (12.3) est supprimé. Il reste à minimiser
l'augmentation du premier terme du à l'arrondi à la valeur
supérieure. L'unique solution consiste à minimiser a. Il
faut donc que le nombre de réduction d'accumulation soit faible.
En résumé le code asap ne s'impose que si l'opérateur Scan
décrit une réduction et que le nombre de réductions
d'accumulation est faible.
Dans ce cas un gain est à attendre car les scans du code naïf
sont remplacés par quelques réductions dans le code asap et
qu'une réduction s'exécute environ deux fois plus vite qu'un scan.
Le fait que le fractionnement des réductions d'accumulation pénalise
le code asap peut être imputé au fait que les petites réductions
(avec moins ou de l'ordre de p données) sont exécutées
inefficacement. Il est facile de voir que dans ce cas mieux vaut
n'utiliser que n1/2 processeurs (n est le nombre de données
de la réduction). Recommençons les calculs avec de nouvelles
fonctions de durée adaptées aux petites réductions :
|
|
|
ds((nj) |
|
)=
2 |
|
|
æ
ç
ç
ç
ç
ç
ç
è |
|
é
ê
ê
ê
ê
ê
ê
ê |
|
ù
ú
ú
ú
ú
ú
ú
ú |
+ |
é
ê
ê
ê
ê |
nj-1 |
|
ù
ú
ú
ú
ú |
ö
÷
÷
÷
÷
÷
÷
ø |
=4 |
|
|
é
ê
ê
ê
ê |
nj-1 |
|
ù
ú
ú
ú
ú |
|
|
dr((nj) |
|
)=2 |
|
|
é
ê
ê
ê
ê |
nj-1 |
|
ù
ú
ú
ú
ú |
. |
|
|
|
|
|
| dc-dn |
= |
|
2 |
|
|
|
é
ê
ê
ê
ê |
nji-1 |
|
ù
ú
ú
ú
ú |
+4 |
|
|
|
é
ê
ê
ê
ê |
ncji-1 |
|
ù
ú
ú
ú
ú |
|
| |
- |
|
2 |
|
æ
ç
ç
è |
|
|
|
é
ê
ê
ê |
|
ù
ú
ú
ú |
+p |
ö
÷
÷
ø |
. |
|
|
|
-
Preuve:
-
L'expression (12.4) est en effet minorée par
|
2 |
|
|
nji-1 |
|
+4 |
|
|
ncji-1 |
|
-2 |
|
|
|
|
-2g (p+1)
.
|
Le code asap n'apporte pas de gain réel si les réductions
d'accumulation sont nombreuses et traitent un faible nombre de
données. Il est, en théorie, possible d'obtenir un gain de
2g (p+1) cycles mais ce gain dépend complètement
des défauts d'arrondi du troisième terme de l'expression
(12.4). Il n'y a aucun moyen de prédire l'importance de
ces défauts, cela dépend du nombre de processeurs et des nombres
de données traitées par les scans du code naïf.
| 14.3 |
Plans pour une génération automatique de code |
|
Cette section discute des techniques à employer pour réaliser
une génération automatique de code pour des programmes contenant
des récurrences (i.e. des scans et des réductions).
Deux étapes doivent être automatisées. Le choix du code à
générer puis la génération du code lui-même.
| 14.3.1 |
Choix du code à générer |
|
Dans un premier temps nous présentons une méthode pour
choisir le code à générer pour un opérateur Scan donné.
Nous utilisons les notations et les résultats de la section
12.1.4. Comme tous les cas de figure ne sont pas envisagés
dans cette section, la solution proposée est forcément heuristique.
La situation est décrite par un certain nombre de paramètres :
Il est à noter que le langage cible peut disposer d'une primitive
de calcul de scan et de réduction pour une fonction associative
donnée et en être dépourvu pour une autre fonction.
La génération du code asap dans le cas général est
trop complexe. Ce code ne sera utilisé que lorsque l'opérateur
Scan décrit des réductions. En conséquence, il faut
commencer par déterminer le type de la récurrence.
En fait, l'opérateur Scan décrit une réduction ssi
3
Pour simplifier la vérification, il est supposé que toutes les
données de l'opérateur Scan sont utilisées (dans le cas
contraire le programme source exécute des opérations inutiles).
La condition devient :
Il est facile de calculer l'enveloppe convexe de Dc à l'aide
de la bibliothèque d'opérations sur les convexe de l'Irisa. Comme
c'est l'enveloppe convexe qui est calculée, et non pas l'ensemble lui
même, le test est approximatif. Il est cependant conservatif dans la
mesure où il ne détectera pas de réduction à tort. Notons
D'' l'enveloppe convexe, si la solution du problème
|
|
lexmax
|
ì
í
î |
l |
l |
|
0 Ù z+ |
|
lk ekÎ D
|
ü
ý
þ |
, |
|
Prenons d'abord le cas d'un modèle de programmation MIMD.
D'après la section 12.1.4, il faut générer du
code asap si, quelque soit le front F(t), le nombre
de points contenus dans Qd(t) est petit (par rapport
au nombre de processeurs disponibles).
Plusieurs méthodes peuvent être employées pour estimer
le nombre de points.
-
Une méthode rapide mais très approximative consiste à calculer
la dimension du convexe. Il suffit de prendre le nombre de variables
servant à exprimer le polyèdre et d'y retrancher le nombre
d'équations du système le définissant. Le nombre d'équations
est facilement obtenu, par exemple, en simplifiant les inéquations
du système par l'algorithme de Chernikova.
- Il existe des méthodes exactes de calcul du nombre de points
entiers dans un polyèdre. Les premiers travaux ont été
menés par Nadia Tawbi dans le cadre du projet PAF [59, 60].
Une amélioration de cette technique se trouve dans [49].
Le problème est que le nombre de points entiers peut être une formule
complexe en fonction des paramètres de structure du programme.
Pour simplifier la vérification il faut extraire le terme de plus haut
degré. Si ce terme dépend effectivement des paramètres de structure
il est considéré que le polyèdre contient un grand nombre de points.
En fait, comme les paramètres de structure peuvent être arbitrairement
grands, le polyèdre peut contenir un nombre de points arbitrairement grand.
Un nombre de points sera considéré petit si son terme de plus haut
degré est une constante. Il est possible de raffiner le test en vérifiant
que la constante est faible devant le nombre de processeurs.
- Une autre technique pour vérifier qu'un polyèdre ne contient que
peu de points est de calculer une intersection de convexes. Il faut commencer
par trouver le point z0 lexicographiquement minimum dans le convexe
(en utilisant le logiciel PIP). La seconde étape consiste à choisir une
constante e petite devant le nombre de processeurs de la machine
cible. L'intersection se fait entre le polyèdre et l'hyper-cube
{z0+h | " i, hiÎNe}.
Si l'intersection est égale au polyèdre c'est qu'il est inclus dans
l'hyper-cube ; il contient peu de points.
Si ce test est positif il faut générer du code asap, sinon
il faut supposer que le modèle de programmation est un modèle SIMD.
Considérons le cas d'un langage de type SIMD ne disposant pas de
primitive efficace de calcul de scans. D'après la section 12.1.4,
Il faut générer du code asap si,
-
quelque soit t, l'ensemble Q(t) contient les points
correspondant à seulement quelques scans ;
- il faut de plus que, quelque soit t, l'ensemble Qd(t)
contienne les points correspondant aux données de nombreuses
réductions d'accumulation ;
- ces données doivent être équitablement distribuées
sur les réductions.
L'ensemble Q(t) peut être calculé automatiquement (plus de
détails sont donnés dans la section 12.3.2). Le test sur le
nombre de points dans Q(t) se fait de la même façon que le
test sur Qd(t) dans le cas du modèle MIMD. Les deux dernières
conditions sont trop difficiles à vérifier. Une approximation consiste
à vérifier que l'ensemble
comporte un grand nombre de points. Ce n'est qu'une approximation car
cela n'assure pas que les données sont équitablement réparties
sur les réductions. L'ensemble (12.6) peut être calculé
automatiquement (voir la section 12.3.2). Le nombre de points
peut alors être estimé par une des méthodes décrites plus haut
(i.e. il faut vérifier que l'ensemble ne contient pas un petit
nombre de points). Si les deux tests sont positifs, du code asap
doit être généré sinon il suffit de générer du code naïf.
Enfin examinons le cas d'un langage de type SIMD disposant de primitives
efficaces de calcul de scans et de réductions. D'après la section
12.1.4, le code asap est à générer lorsque, quelque
soit t, Qd(t) contient de nombreux points associés aux
données de seulement quelques réductions. Pour cela il suffit de
vérifier que Qd(t) contient de nombreux points et que
l'ensemble (12.6) contient, lui, seulement quelques points.
Si le test est positif il faut générer du code asap sinon du
code naïf.
| 14.3.2 |
Génération automatique de code |
|
La génération de code naïf passe par le calcul des
ensembles Q(t) et P(z). Le calcul de l'ensemble
Q(t) se décompose en le calcul de l'ensemble
{ zÎ D | q(z)=t }
,
et le calcul de l'ensemble :
Le premier ensemble est déjà sous la forme d'un ensemble
d'inéquations affines car D est défini ainsi.
Le second ensemble ne peut pas être calculé tel quel, nous
faisons la même hypothèse que dans la section 12.3.1.
C'est à dire que le maximum est calculé dans D et
pas dans D'. Trouver un système d'inéquations caractérisant
ne nécessite pas de nouveau calcul. Il suffit de reprendre la solution
générique L(z) du problème (12.5).
L'ensemble s'écrit alors :
|
|
ì
í
î |
z+ |
|
Lk(z).ek | zÎ D' |
ü
ý
þ |
.
|
Les corps des nids de boucles exécutent les scans. Pour un vecteur
d'itération z donné, un scan sur les données des
coordonnées contenues dans P(z) doit être effectué.
Une méthode de calcul de P(z) est décrite dans la section
11.3. Si les directions de l'opérateur Scan sont
alignées sur les dimensions des tableaux ou si le changement
de base présenté dans la section 12.1.1 est applicable
le scan peut être implanté grâce à la plupart des primitives
de calcul de scan existantes. Quand le domaine défini par P(z) n'est
pas régulier (rectangulaire ou parallélipédique), les éléments
non utilisés du tableau doivent être remplis avec l'élément
neutre de l'opération.
Si les directions ne peuvent pas être alignées sur les dimensions
du tableau ou si la machine ne possède pas de primitives de scan,
il faut utiliser une procédure respectant exactement la sémantique
de l'opérateur Scan. Cette procédure est moins optimisée que
ne le seraient des primitives natives.
Passons à la génération de code asap. Le squelette du code
asap pour un opérateur Scan décrivant des réductions est :
DO t=t1,t2
Soit I l'ensemble Qd(t)
Quotienter I par º S
Soit C l'ensemble des classes d'équivalence de I
DO ALL E Î C
Soit s l'image par S d'un élément de E
temp(s)=réduction(temp(s),E)
END DO
END DO
L'ensemble Qd(t) est facilement caractérisable par un ensemble
d'inéquations. La fonction S dans le cas d'une réduction
(avec les habituelles approximations sur D') n'est rien d'autre
que maxe1,...,ek D. Le point
S(z) est donc la solution générique l(z) du problème
(12.5).
Au lieu de calculer le quotient de Qd(t) par º S, il
est plus simple de calculer l'ensemble (12.6).
Il est possible de calculer automatiquement (12.6) en utilisant
PIP de même manière que pour résoudre (12.5). Le contexte
seul diffère, il devient zÎ Qd(t).
Le résultat s'écrit comme une union paramétrée par t d'ensembles
définis par des systèmes d'inéquations affines.
Il est donc possible d'énumérer les points entiers de l'intersection
grâce à des nids de boucles. Il reste à trouver pour un de ces points
i la classe d'équivalence E correspondante. Il s'agit de l'ensemble :
Qd(t)Ç {zÎ D | S(z)=i}
.
Encore une fois, cet ensemble est une union de polyèdres définis
par des systèmes d'inéquations affines. Il se pose le même
problème que pour le code naïf : si l'ensemble n'est pas
régulier les primitives de calcul de scans classiques ne peuvent
pas être utilisées.
| 14.3.3 |
Illustration sur un exemple |
|
Le but de cette section est de montrer que le détecteur de
scans couplé à un générateur de code
permet une parallélisation ``sémantique'' de certains
programmes.
L'exemple que nous avons choisi est l'algorithme de résolution
d'un système linéaire dont la matrice associé est triangulaire.
Cet algorithme est la dernière phase (dite de remontée) des
procédés de résolution des systèmes linéaires quelconques.
L'implantation la plus courante (car la plus naturelle pour un humain)
de l'algorithme de remontée est la suivante :
DO i=0,n-1
x(n-i)=b(i+1) (v1)
DO j=1,i
x(n-i)=x(n-i)-a(i+1,n-i+j)*x(n-i+j) (v2)
END DO
x(n-i)=x(n-i)/a(i+1,n-i) (v3)
END DO
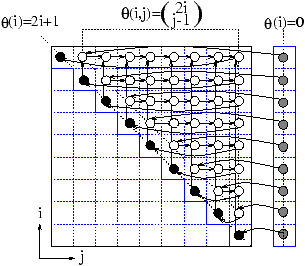
Le graphe de dépendance est dessiné ci-dessous.
Les sommets de ce graphe de dépendance représentent à la
fois les opérations et les données du programme.
Les sommets grisés représentent les opérations de
v1 qui référencent les données b(i+1).
Les sommets évidés représentent les opérations de v2
qui utilisent les données a(i+1,n-j+1).
Enfin, les sommets pleins représentent les opérations de v3
qui opèrent sur les données a(i+1,n-i).
La base de temps des opérations de v2 est multi-dimensionnelle.
L'ordonnancement classique ne réussit pas à extraire de parallélisme
du programme séquentiel.
Tentons une détection de scans, le système final est :
a : { i,j | 1<=i<=n, 1<=j<=n } of real ;
b : { i | 1 <= i <= n } of real ;
v3 : { i | 0 <= i <= n-1 } of real ;
v3[i] = case
{ i | i = 0 } : b[1] / a[1,n] ;
{ i | i > 0 } :
Scan( { i',j' | 1<=i'<=n-1, 0<=j'<=i }, ( [0 1] ), +,
-a[i'+1,n-i'+j'] * v3[i'-j'], b[i'+1]
)[i,i] / a[i+1,n-i] ;
esac ;
Il faut maintenant calculer la base de ce système par la méthode
présentée en 11.
Les contraintes de causalité pour les bases de temps
q(v,.) de l'opérateur Scan et q(v3,.),
de l'équation v3 sont :
|
|
| " iÎNn-1*, " jÎNi*, q(v,(i,i))
³ q(v3,i-j) + 1 |
| q(v3,0) ³ 1 |
| " iÎNn-1*, q(v3,i) ³ q(v,(i,i)) +1 |
|
|
|
| q(v,(1,1))³ 2 |
| " iÎ{2,...,n-1}, " jÎNi*, q(v,(i,i))
³ q(v,(i-j,i-j)) + 2 |
| q(v3,0) ³ 1 |
| " iÎNn-1, q(v3,i) ³ q(v,(i,i)) +1 |
|
q(v,(i,i))=2i, et q(v3,i)=2i+1
L'ordonnancement est à nouveau uni-dimensionnel.
Pour décider du code à générer il faut commencer par résoudre
le problème (12.5) :
|
lexmax
|
{ |
l |
l ³ 0 Ù
i Î Nn-1* Ù
j + l Î Ni
|
} |
.
|
|
L(i,j)= |
ì
í
î |
| if |
1£ i £ n-1 Ù 0£ j£ i |
i-j |
| if |
i<1 Ú i> n-1 Ú j>i |
^
. |
|
|
Supposons que le langage cible soit de type MIMD. Il faut estimer le
nombre de points de l'ensemble Qd(t). Cet ensemble est
défini par un système d'inéquations affines :
|
| {(i,j) | iÎNn-1*, jÎNi, q(v3,i-j)=t-1} |
| = |
| {(i,j) | 1£ i£ n-1, 0£ j£ i, 2(i-j)=t-2}
. |
|
|
|
ì
í
î |
æ
ç
ç
è |
|
+h1-1,h2 |
ö
÷
÷
ø |
| 0£ h1£ e,
0£ h2£ e |
ü
ý
þ |
,
|
|
|
ì
í
î |
æ
ç
ç
è |
1+h1,h2- |
|
+2 |
ö
÷
÷
ø |
| 0£ h1£ e,
0£ h2£ e |
ü
ý
þ |
,
|
|
|
|
| { (i,j)+L(i,j).(0,1) | (i,j)Îf( Dc), q(v,(i,j))=t} |
| = |
| { (i,j)+(0,L(i,j)) | (i,j)=(i',i'), 1£ i'£ n-1, 2i=t} |
| = |
|
|
|
|
|
|
|
| = |
| { (i,j)+L(i,j).(0,1) | (i,j)ÎQd(t)} |
| = |
| { (i,i) | iÎNn-1*, jÎNi, 2(i-j)=t-2 } |
| = |
ì
ï
í
ï
î |
| if |
t mod 2=0 |
ì
í
î |
(i,i) | |
|
-1£ i£ n-1 |
ü
ý
þ |
|
| else |
Ø
. |
|
|
|
|
|
Qd(t) Ç { (i',j')Î D | S(i',j')=(i,j) }
,
dans le contexte où (i,j) est un élément de (12.9) et
t est pair.
|
|
| Qd(t) Ç { (i',j')Î D | S(i',j')=(i,j) } |
| = |
| {(i',j') | i'ÎNn-1*, j'ÎNi', 2(i'-j')=t-2, (i',i')=(i,j)} |
| = |
|
|
v3(0)=b(1)/a(1,n)
DO i=1,n-1
temp(i,i)=b(i+1)
END DO
DO t=2,2*n-1
IF (MOD(t,2).EQ.0) THEN
t2=DIV(t,2)
DO ALL i=t2-1,n-1
temp(i,i)=temp(i,i)-a(i+1,n-t2)*v3(t2)
END DO
END IF
IF (MOD(t,2).EQ.1) THEN
i=DIV(t,2)
v3(i)=temp(i,i)/a(i+1,n-i)
END IF
END DO
Ce programme parallèle est optimal. Il est à noter qu'il
peut être obtenu par la méthode géométrique
classique. Pour cela il faut modifier le programme Fortran initial
(i.e. accumuler les produits non plus de la gauche vers la droite
sur la figure mais de la droite vers la gauche) :
DO i=0,n-1
x(n-i)=b(i+1) (v1)
DO j=1,i
x(n-i)=x(n-i)-a(i+1,n-j+1)*x(n-j+1) (v2)
END DO
x(n-i)=x(n-i)/a(i+1,n-i) (v3)
END DO
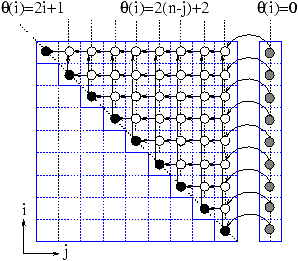
Le graphe de dépendance détaillé de ce programme est
donné sur la figure ci-dessous :
En supposant que les valeurs des tableaux a et b soient
calculés au temps 0, un calcul de base de temps classique va
trouver un bon ordonnancement pour le programme. En effet
la base de temps des opérations de l'instruction v2 (qui
constituent la majeure partie des opérations du programme) est
2(n-j)+2. Ceci signifie que le programme parallèle déduit de
cette base de temps peut s'exécuter en un temps de l'ordre de
n2/p.
D'une certaine façon la détection de scans suivie d'une
génération de code asap ont parallélisé sémantiquement
le programme séquentiel. C'est à dire que les opérations
d'addition ont été réorganisées pour obtenir un code
parallèle plus efficace.
Considérons le dernier cas : un langage cible de type SIMD avec des
primitives de calcul de scans. Le test du code échoue car
(12.9) contient de nombreux points. C'est donc un code
naïf qui doit être généré. L'ensemble (12.8)
est déjà calculé. Reste la caractérisation de l'ensemble
P(i,j), avec (i,j) dans (12.8) :
P(i,j)={(i,j') | j'ÎNi*}
.
Le code naïf se déduit de ces deux polyèdres.
v3(0)=b(1)/a(1,n)
DO t=2,2*n-1
IF (MOD(t,2).EQ.0) THEN
i=DIV(t,2)
temp(0)=b(i+1)
DO ALL j=1,i
temp(j)=a(i+1,n-i+j)*v3(i-j)
END DO
v(i)=SUM_PREFIX(temp(0:i))
END IF
IF (MOD(t,2).EQ.1) THEN
i=DIV(t,2)
v3(i)=v(i,i)/a(i+1,n-i)
END IF
END DO
La complexité de ce programme est proche de la complexité
optimale si la fonction SUM_PREFIX est parallélisée.
Le code asap est, cependant, encore meilleur. L'heuristique de
choix du code à générer est faussée du fait que la
parallélisation entre réductions d'accumulation n'a pas
été envisagée dans le cas du langage SIMD possédant des
primitives de calcul de scan.
Heureusement, choisir à tort le code naïf n'est jamais très
préjudiciable si des primitives de calcul des scans existent.
Cela revient à utiliser le parallélisme intra-scans plutôt
que le parallélisme inter-scans. Ce parallélisme est plus
complexe à extraire donc un peu moins efficace.
- 1
- Une tranformation uni-modulaire est telle que sa
matrice associée est à coefficients entiers et possède
un déterminant ègal à 1 ou -1.
- 2
- L'ensemble P(z) est défini à la section 11.3.
- 3
- Rappel :
l'ensemble D' est l'image par f du domaine
de la clause dans laquelle se trouve l'opérateur,
i.e. f( Dc).